| ACT2G: Attention-based Contrastive Learning for Text-to-Gesture Generation |
In recent years, communication in virtual spaces has become increasingly active, and the utilization of avatars has advanced. Additionally, remote-controlled robots and communication robots have become widespread and are being developed extensively. It is known that gestures play a crucial role in conveying information, but automatically generating gestures for avatars and robots remains a challenge. Traditional methods have struggled to learn the relationship between speech and gesture semantics, making it exceptionally challenging to accurately reflect the meaning of spoken content. Therefore, in this approach, we propose Attention-based Contrastive Learning for Text-to-Gesture (ACT2G), which explicitly considers semantic information.
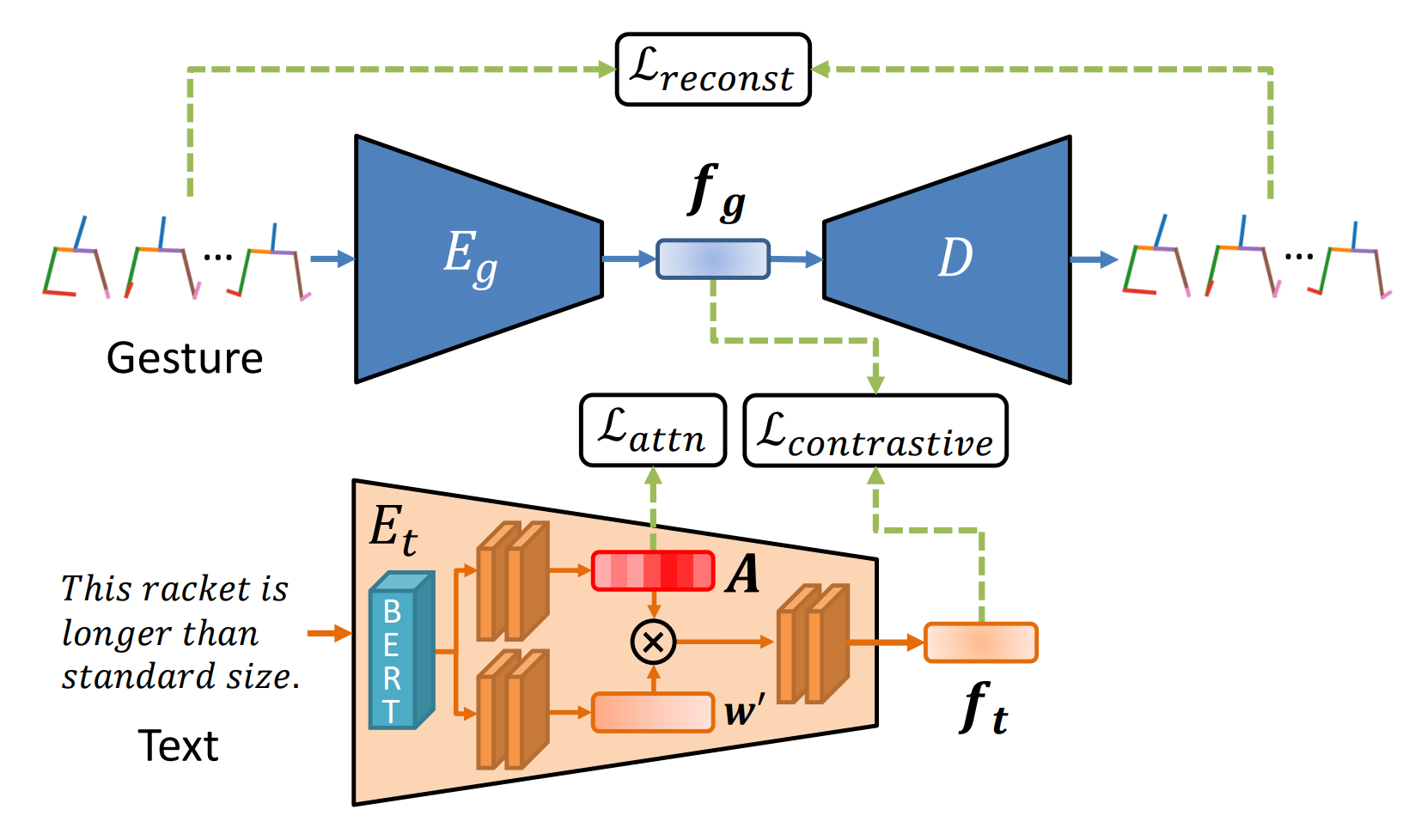
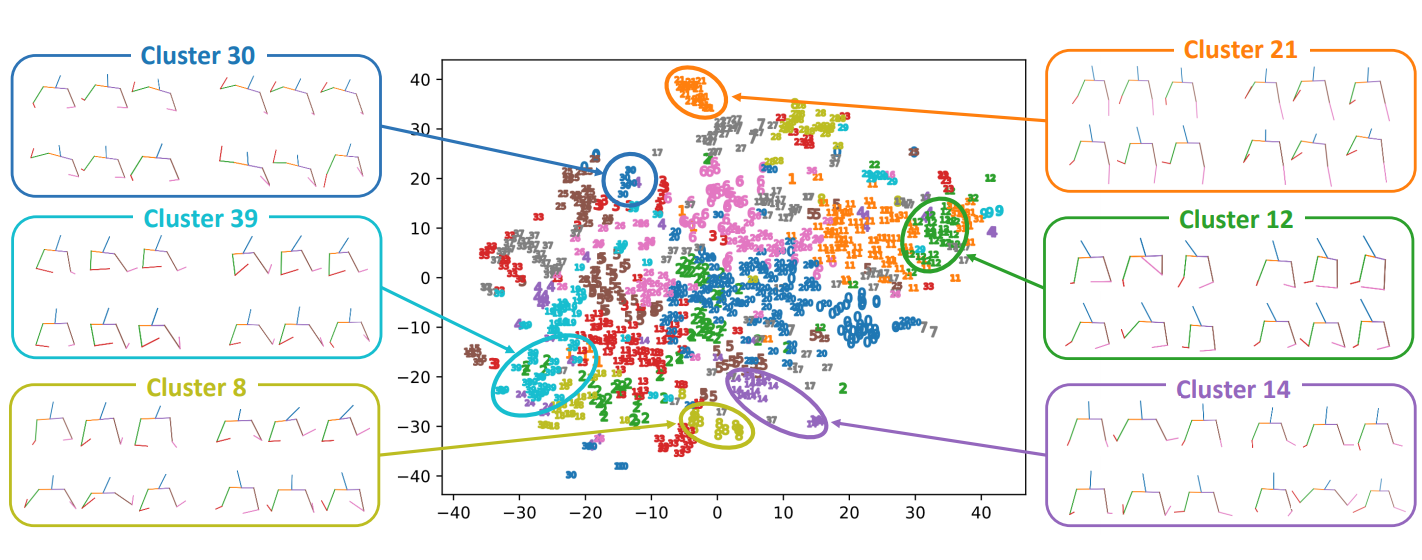
Designing gestures manually requires specialized knowledge and is very time-consuming, so using AI for gesture generation simplifies this task. However, conventional approaches have not been able to reflect the gestures that users want to design. In this approach, we propose a method that focuses on generating gestures based on words with a high likelihood of being expressed through gestures. The TED GestureType Dataset annotates words representing gestures. Using this data, we estimate Attention Weights that represent the importance of noteworthy words and encode the input text. 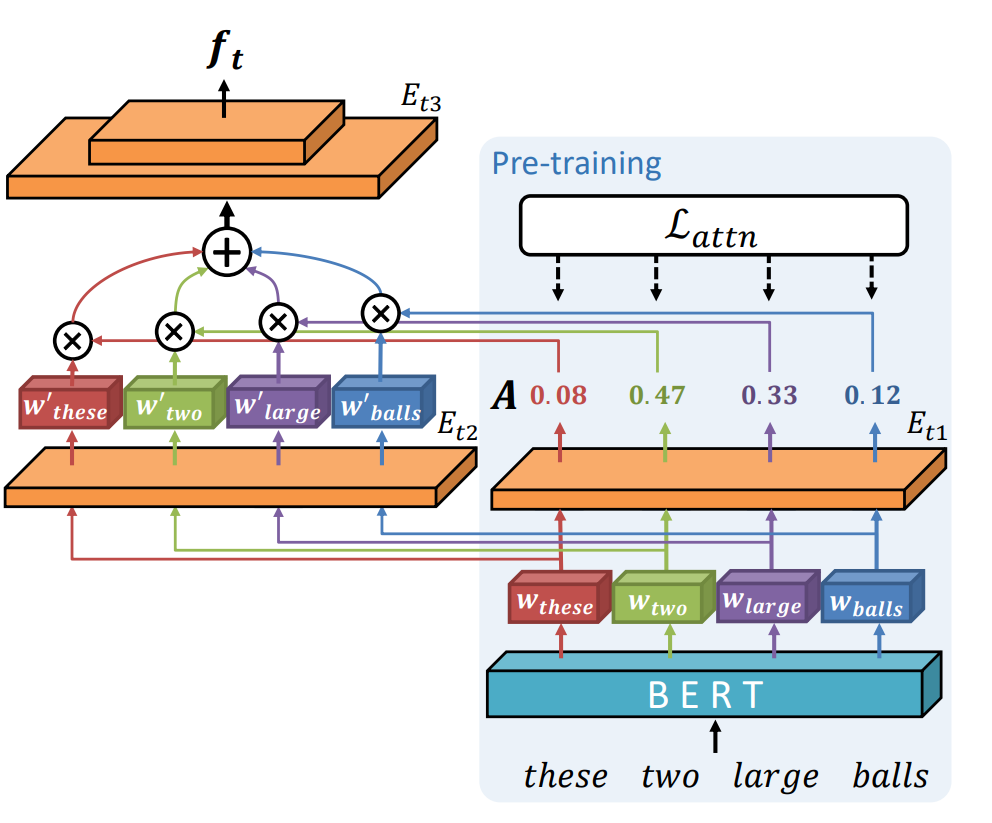
The actually generated gestures are shown in the figure below. The portions where gestures reflecting the content of the text appear are enclosed in colored rectangles. Gestures generated by this approach can be seen, such as spreading both arms when expressing "loud" or "a lot of" and extending the right arm when saying "right here." In experiments involving over 100 participants, user evaluations were conducted, and a comparison was made between the gestures generated by this approach and existing methods. The results of the experiment showed that the gestures generated by this approach significantly outperformed the other three existing methods with a p-value <0.01. 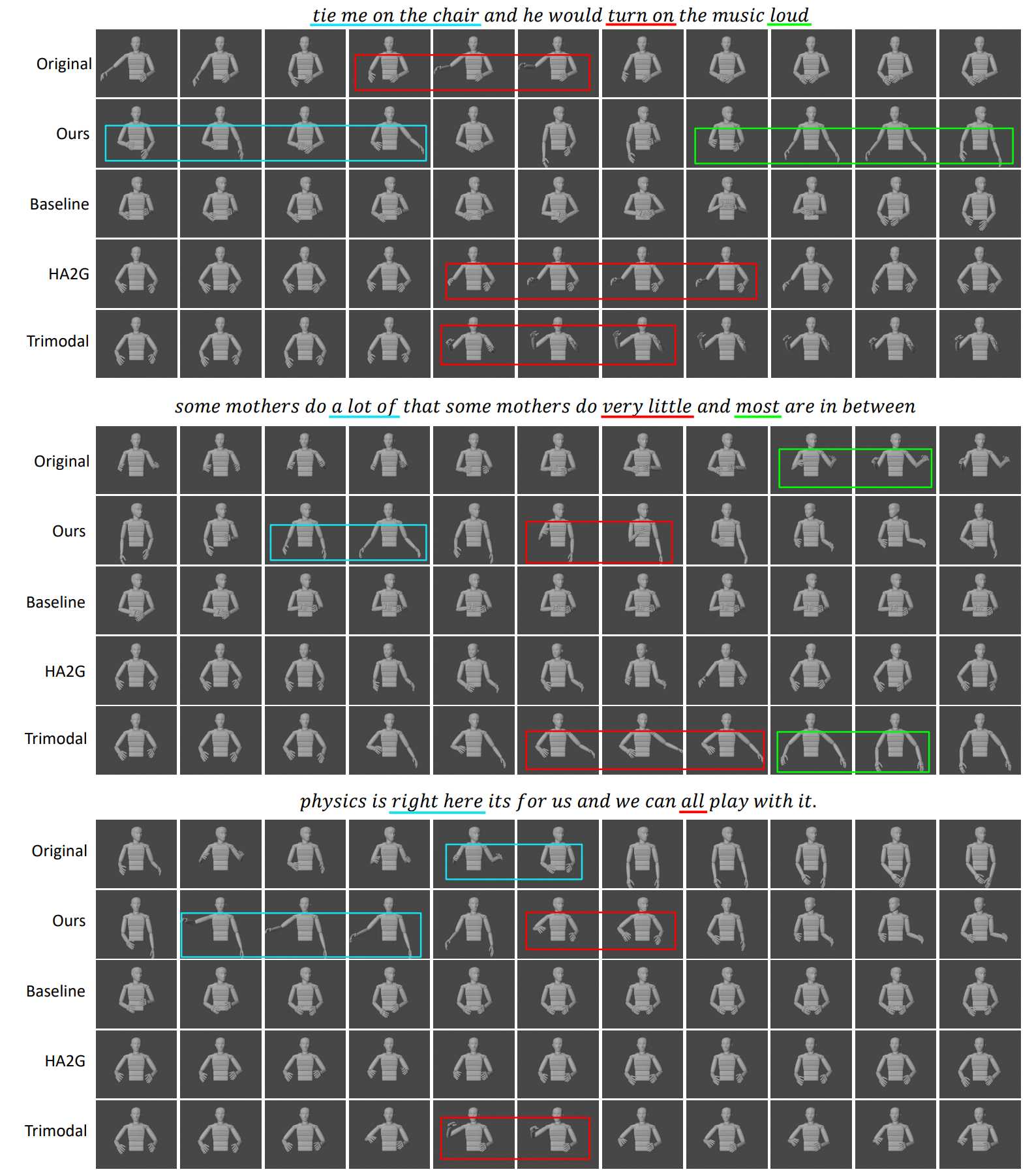
Resources
Publications
|
| Computer Vision and Graphics Laboratory |